Blog URL at hrishikamath.com
Hello there, thanks for visiting this page. My blog has moved to hrishikamath.com. Won't put effort into even making this page look nice for you :P.

This blog post is meant to introduce you to a few differential private mechanisms. This assumes you have some understanding of
the definition and aims of differential privacy. This is not an exhaustive list or indepth analysis. Just introduction to few
mechanisms to get an understanding of DP and why mechanisms based on DP work. It also motivates the privacy-utility tradeoffs that could be made.For proofs as to how the mechanism bounds are derived you can refer to the book
<a target="__blank href="https://www.cis.upenn.edu/~aaroth/Papers/privacybook.pdf">The Algorithmic Foundations of Differential Privacy.</a> All of the mechanisms described in the section are DP (![]() ,0)
,0)
There is no single mechanism that guarantees privacy and utility over several possible queries and problems , but there are some class of queries and common DP algorithms that provide a solution with decent utility-privacy tradeoff.
To understand the mechanisms we will consider it from query-release problem point of view where analyst could analyze the database in form of queries. Similar to querying a regular SQL database
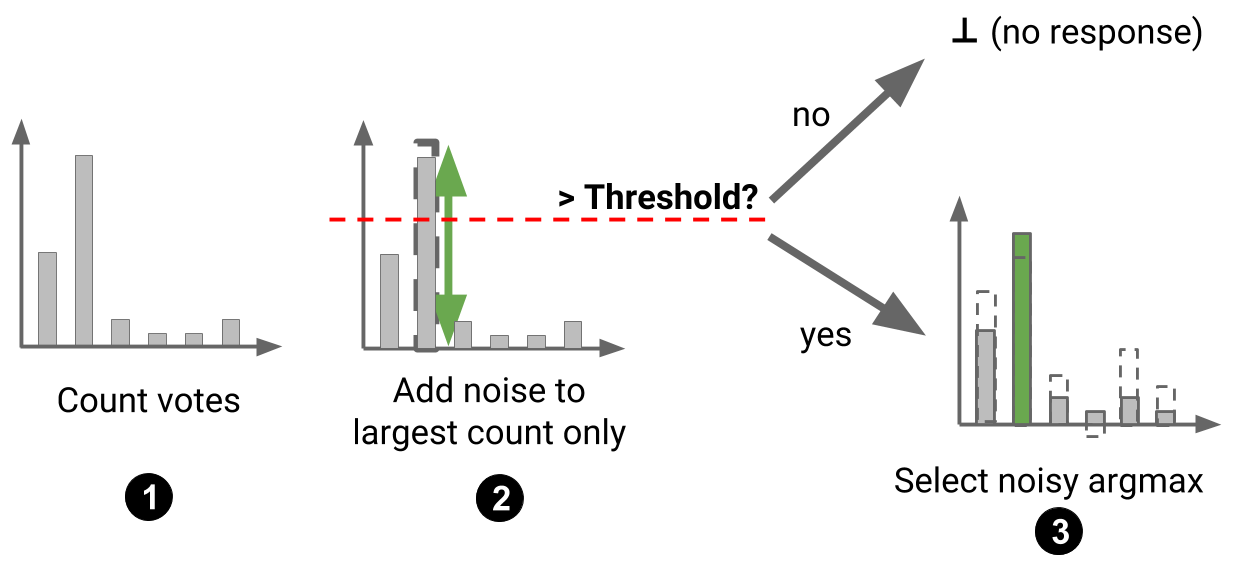
Sparse Vector Technique(SVT) is one technique that greatly helps save the privacy budget by a large extent. The fundamental idea is to report the answer only if it is above a certain threshold. The value being a noisy value.This way queries below certain threshold not being reported helps save privacy budget as they are the one's with the most privacy budget. But , one major disadvantage of vanilla SVT is that small values below threshold could pass threshold with a large noise while large values above threshold could be below the threshold by adding a large negative noise. Although the possibility of this is small there are some adaptive SVT techniques which improve upon these drawbacks. SVT is a building block behind scaling training of Machine Learning models. PATE(Private aggregate of Teacher Ensembles) rely on training ensemble of machine learning models. They output their votes in the form of histogram queries. When majority of the models output a certain class it is more likely to be correct while there is not single winner could be revealing on the training data.
AboveThreshold(D, {fi}, T, ε):
Tˆ=T+Lap(2/ε)
for Each query i do
Let νi = Lap(4/ε)
if fi(D) + νi ≥ Tˆ then
Output ai = ⊤.
Halt.
else
Output ai = ⊥.
end if
end for
Check out Part-IV of the tutorials where I will explain how DP algorithms privacy guarantees hold good over multiple queries
Hello there, thanks for visiting this page. My blog has moved to hrishikamath.com. Won't put effort into even making this page look nice for you :P.