Differential Privacy Part-I: Introduction
Personal data is a personal valuable asset, it could be used for economic, social or even malicious benifits. Most internet companies survive on personal data of users in exchange of services. Usually this leads to distributing data to third party services such as advertisers which on a personal level could be a privacy violation. The most common practice to keep data private is by removing personally identifiable information (PII), a practice known as anonymization. But, it still does not ensure that the identities of the individual in the dataset cannot be re-identified. The increasing available data online gives surface to linkage attacks. Linkage attacks involve reidentifying a user from the dataset by combining information from other datasets consisting of overlapping columns of data. One such popular attack is the Netflix attack. Usually third party services such as advertisers don't need personal identifying information, but just enough statistical representation of information. This motivates usage of data analysis which reflects the statistics of global dataset population, but does not capture any personally identifying information. Differential Privacy (DP) is based on Fundamental Law of Information Recovery which states that "overly accurate answers to too many questions will destroy privacy in a spectacular way".
DP is one take on privacy which ensures that no single individual is affected for being a part of the dataset or data collection process. It not only protects the individuals from linkage attacks but also provides a plausible way of quanitifying privacy loss.
To make it more intuitive as to why privacy is important, let me take an small example. Say in an annual survey of a small town consisting of 10,000 people the sum of all incomes is 2000 million. Suppose the survey is conducted again in the following year and the result ends up reducing to 1900 million because there is one person lesser than before. Using auxillary data sources one could find out who left the town from which it isn't hard to infer that their income was 100 million. This could be discouraging for participants to participate in such statistics as it could leak sensitive information. These are known as differencing attacks. Note: In practice differential privacy is used for large datasets and does not provide good guarantees for smaller datasets.
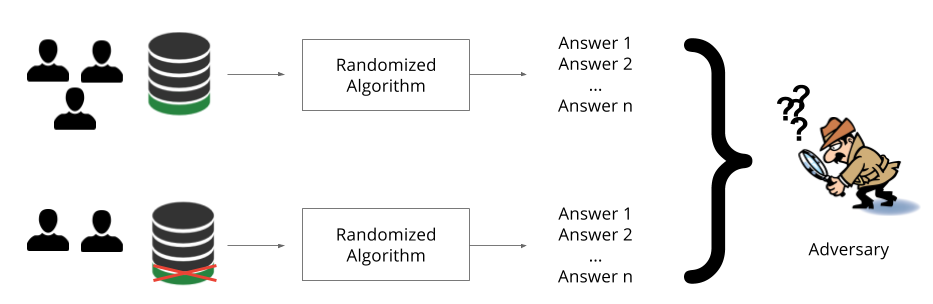
To formalize the above example in terms of querying datasets. The above example can be phrased as two queries: A summation query with all rows of a dataset and a summation query excluding a single participant. The difference in both queries results in leakage of a indvidual's datapoint. The dataset with the indvidual is D1 and without individual is D2. One way to solve the above problem is to ensure that the output of a given algorithm or query such as above does not change significantly with inclusion/exclusion of any individual. So the output of query sum(Income|D1) should be rougly equal or close to sum(Income|D2). That is the statistic or analytical is not affected by an single individual but should reflect the overall population. So how could we possibly mitigate this? we could add random noise to both D1 and D2 such that the difference does not leak in individuals data i.e outputs of queries are as close as possible. It is not necessary that the adversery specifically phrases queries in order to marginalize the individual. It can so happen that the resultant of certain queries could result in violation of privacy or that the analyst is already aware of some entries in the dataset.
Given the above background as to why we need to protect privacy when analyzing datasets, let us define what exactly DP is. DP defines that the probability of a given output of a mechanism on D1 is almost equal or close to the output for a given mechanism of D2 by a factor of exp(epsilon).

The above equation is the foundation of Differential privacy. We charecterize this by DP(ε,0). In general DP is represented by DP(ε,𝛿), in the above definition delta is 0. The delta term gives the tail bound of probability distribution which we can ignore for now, you can read about it in this article.
A user's privacy is violated if more information is learnt about a given user when the analysis is performed. If a general inference is made about the population and the same applies to the specific user the user's privacy is not violated. For instance if in the previous example the average income would be 0.2 million. It is likely that anybody belonging to the town would have a income around the range. This is a general inference and does not violate any single persons privacy.
Data collection and analysis must be limited to representing statistics of entire population but in a way that every individuals confidentiality is maintained. You can get complete privacy by absolutely outputting random numbers or get complete utility for a certain task by outputting raw data. There exists a tradeoff between the two. Differential Privacy is not a direct solution to privacy but a mathematical theory to quantify and guide development of private algorithms. Like Asymptotic Analysis by itself is not an algorithm by itself but a theory to guide development of algorithms. The reason why it is important to quantify utility is that the adversery interacts with the dataset in the same manner as the analyst who could benifit from the dataset.
DP can seem very pessimistic or unnecessary, the issues DP can quantify and guide to solve scale beyond just basic population statistics, even training Neural Networks. What are the possible privacy violations in neural networks ? Certain approaches could be used to reconstruct neural network training data which could be sensitive. Think about it this way, you are using a NLP service of predicting next word by a MLAAS(Machine Learning As a Service) provider such as Amazon AWS or Microsoft Azure. You could possibly get it to predict a next word that was supposedly to confidential or a facial recognition algorithm service where you could show it images of similar people to get an idea of target people to know if they belonged to the training data.

Further, differential privacy does not aim to guarantee protection of most individuals data but designed to guarantee every individual's data. The few people with interesting data do form the most interesting insights in analysis and needs to be protected.
This introduces another term used to charecteristic a dataset called sensitivity. This can be given
What it intuitively means is that how likely the value of outcome would change if given person was not in the dataset.Sensitivity is a term that is dependent on the dataset.
A major guarantee of DP is that it protects individuals data from auxillary information. That is if the data from a given dataset is combined with data from other dataset, the data of the individuals still remains private. DP still protects individual's data even if the adversery has access to some rows of dataset or influences the creation of new rows of data.
Check out Part II of the tutorials where I will cover some basic DP mechanismsI thank my friend Shravan Sridhar for reviewing and helping me improve this article