Machine Learning-Learning to predict classes not seen during training
In conventional machine learning we train an algorithm on input/output pairs (Supervised learning) or only on raw data(Unsupervised learning) and make predictions using trained model. But, can we possible train an algoritm to make the right predictions on classes of data it's never seen before? Quite possible, the specific technique is called zero shot learning.
In this blogpost I would like to cover what zero shot learning (ZSL) is, its working and limitations.
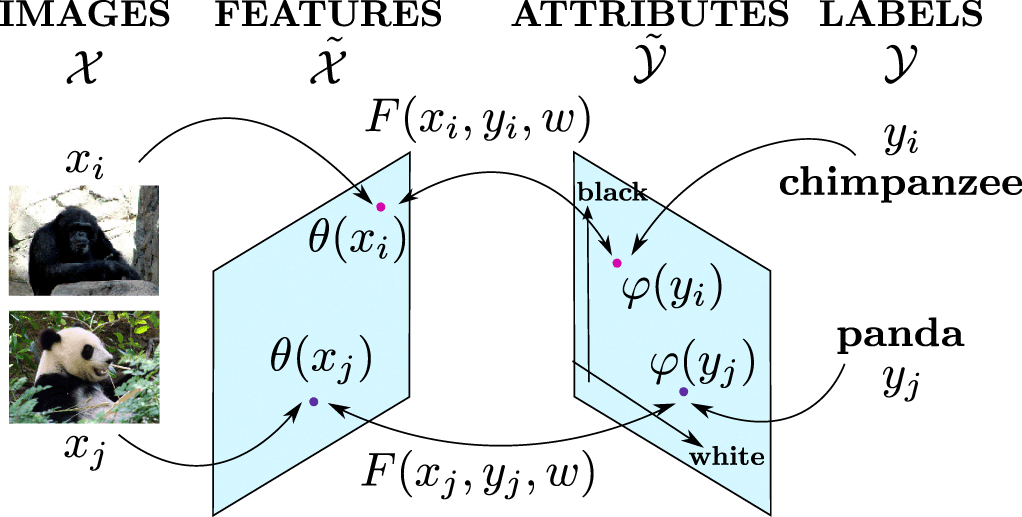
ZSL is a type of learning method that allows to predict classes the algorithm has not seen during training phase. ZSL cannot be done directly on just image/label pairs, they require an intermediate that helps algorithms relate images to classes. Lets call these intermediates as attributes. These attributes could be word vectors, sentance or a vector with description of the class. The relationship between data and attributes are learnt from the dataset by a machine learning model for which we have pairs of data and their corresponding attributes and labels. At test time, the model predicts attributes for a given datapoint. From the attributes we further find the class the attributes correspond to. In this blogpost I would like to focus on ZSL that uses a vector description of a given class. Note that its quite possible for individual images to have their own attributes rather than class attributes.

A vector describing a given class consists of each point in the vector describing a particular feature. A binary number of 1 on the 1st position might describe that its a brown animal, 2nd position describing if its associated with water with as many attributes as possible describing a class. Attributes could be binary or continious with value denoting the strength of each given attribute. The more attributes, the finer detail it could learn about a given class but also requires more data to learn the relevant relationships. The network uses the seen classes to learn relation between images and attributes or other information such as human gaze, word embeddings or whatever information that could be related between classes and images. Based on what the network learns it could be further mapped to the objects and attributes.
Say your classifier has pig, dogs, horses and cats images and its attributes during training time and has to classify a zebra during test time. During training time it learns the relation between image pixels and attribute such as 'stripes,tail,black,white...'. So during test time given an image you predict its attributes and find the class the attributes correspond to. ZSL is very much like how humans learn, we learn concepts and relate them to new instances we haven't seen before.
Zero shot learning requires images that represent all the attributes in the training set. Attributes are a finer description of each class and can even be used to augment supervised learning in some cases [1]. But, attributes can be expensive in terms of annotation when every data point is labelled rather than classwise as it requires data labeller to provide values for every attribute for every datapoint which increases the labelling cost by atleast x(Number of attributes) as compared to labelling data for supervised learning. Attributes can also be subjective to data labeller.
References
[1] “Learning Visual Attributes”, Vittorio Ferrari and Andrew Zisserman, 2007