Meta Learning with MAML
Training neural networks for a single task requires several thousands of examples for a each class when training a model from scratch. This is typically not how learning should occur. Humans use prior knowledge in some task to be able to generalise to another task with little examples of the new task. We should be able to learn from scratch even when the dataset has few examples per class. Training directly on several tasks with little images leads to overfitting. So we need to be able to have the algorithm learn in a way that it is ensured features from one task generalise to another. Meta learning is not limited just to image classification but to any sequence of task. For example, you could pair tasks of language generation, depth estimation, skill learning or any task solved in conventional machine learning.
I would like to describe a simple meta learning algorithm called MAML (Model Agnostic Meta Learning) [1] . MAML is an optimization based approach which influences the way model learns based on performance on test set. It forms the basis for most standard algorithms for meta learning because its easy to incorporate into any task due it its simplicity and is model agnostic. Other popular approaches are model and metric based such as relation , Siamese networks (metric), meta learner and NMT.

In MAML an algorithm is trained for a set of tasks like regular supervised learning. The performance of model is evaluated on test data. Based on the error on test data the model is updated. Notice that the model is trained several epochs on training data but update is performed once on test data. Isn’t this against the fundamental machine learning rule of not training on your test data? Remember here the focus is not to test the algorithm performance for a given task, but to teach an algorithm to learn as well as possible to learn for newer tasks. At meta-test, we train the algorithm on a new task and evaluate the test accuracy on the task. theta is the meta learning parameters and theta' is the task specific parameters. It is the update step over the meta-test that forces the model to learn more general parameters rather than just task specific parameters. But, do not update the model parameters based on the error. If you are familiar with recurrent neural networks, a good analogy would be that the meta learner parameters are like the hidden states across time-steps. meta parameters are like the shared parameters across tasks. The meta parameters are trained on a given task and updated. These parameters are the initial parameters for the next task.
To make it more clear how meta learning with MAML is put into practice I will use the example of few shot learning.
In few shot learning we aim to learn a classifier given there are very few images per class, even when we have as little as 1 image. For the purpose we divide the dataset into meta train, meta test dataset with tasks held out for evaluating performance of meta learning algorithms. Few shot learning is commonly classified as N way K shot learning. That is N being the number of classes and K being number of instances of classes. The below is an example of 3 way 2 shot learning. We don't just have 3 images of each class in the case. But, we are dividing a dataset into a set of tasks that are 3 way 2 shot. Just Like regular supervised learning learns better with more data, the model learns better with more tasks. But, in few shot learning we have little data per class and lots of classes. Regular supervised learning would overfit if trained on datasets relavent for few shot learning.
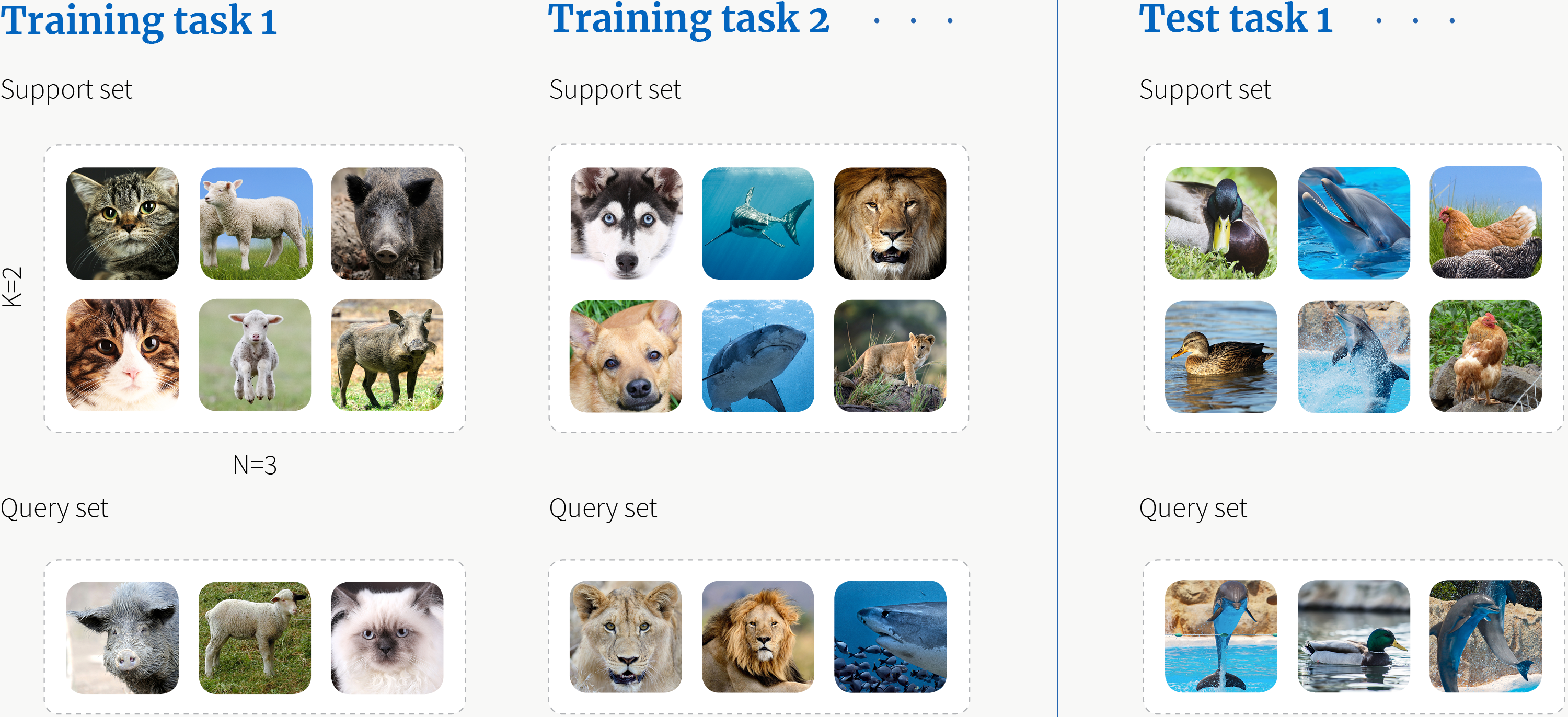
We divide the dataset into two splits 1) Support and 2) Query Set. An algorithm is trained on two tasks , first task consisting of images of cats, sheep, pigs. The second task consisting of animals such as dogs, lions and sharks. The test task being duck, chicken and dolphin. The algorithm is trained on the support set and evaluated on query set. The support set is used to update the task specific parameters. The loss on test set is used to update the meta parameters. Further, the performance of meta learner is evaluated on test tasks. The test tasks are N way and K shot, but disjoint from tasks on which the meta learning algorithm was trained on.
References
- Chelsea Finn, Pieter Abbeel, Sergey Levine , Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks